


2.「信頼できる情報」とは何か
【資料編】エビデンスの見方
2.「信頼できる情報」とは何か

『これからのヘルスリテラシー 健康を決める力』(講談社、2022)
サイト『健康を決める力』をアップグレードしました
Amazon
版元ドットコム
情報チェックの「かちもない」と自分らしく決める「おちたか」の動画を公開しました
YouTube TikTok
1. 代表的なバイアス
代表的なバイアスは、選択バイアス、情報バイアス、交絡バイアスの3つです。それぞれ、例と共にそれへの対処も含めて解説します。1)選択(セレクション)バイアス
研究対象者の選び方で生じるバイアスのことです。研究対象にしたい人たちのなかから、選ぶ前や選んだ後に研究対象から落ちてしまったり、ある特徴を持った偏った対象が選ばれてしまったことによって生じます。例えば、重度のがんに効くとされる抗がん剤の効果を実験するために、がんの患者さんの中から参加者を募り、実験を行った結果、効果が上がったとします。しかし、その実験は長期間かかる実験で、最後まで参加したという人は体力がある方ばかりであったとします。このようなときに、選択バイアスが生じているといいます。がんをはねのけるくらい体力があった人だけの結果であるかもしれないからです。
また、職場で働く人を対象に健康調査をする場合、その時に健康を害して退職したり休職していて選ばれないことで、結果は健康な労働者だけになってしまって、本当に知りたい人が選ばれないことになります。これを「健康労働者(ヘルシーワーカー)効果」といいます。高齢者でも、老人クラブに集まっている人を調査をすれば、元気な人ばかりが対象になる可能性があります。
これらの対処法として、研究者は、対象者の選び方によって選ばれやすい人や選ばれにくい人が出ないようにします。そのため事前には対象者が偏らないような環境や条件を整えることや、研究が始まった後は研究そのものが負担にならないように考慮することが必要です。
2)情報バイアス
観察方法や測定方法で生じるバイアスです。対象者によって回答が変化しやすい方法や、対象者によって違う測定方法で行ったりすることで生じます。例えば、昔のことを思い出してください、という質問では、忘れてしまっているかおぼろげだったりして、本当の状況を正確に思い出せないことがあります。ところが長く病気だった人は、それに関する過去の記憶が明確だったりして、結果がゆがんでしまう可能性があります。この場合はとくに、「思い出しバイアス」と呼ばれることもあります。この対処法として、研究参加者本人の「振り返り」はできるだけ避けることが挙げられます。
また、肥満の人と肥満でない人の心疾患発生の関係について、時間を追って検討しようとしているとき、肥満の人の方が、心疾患が起こりやすいと思い込んでいるため何度も心臓検査を受けているかもしれません。検査をたくさん受けると、疾患が見つかる頻度が高くなりますから、いくら肥満の人が心疾患を発生しているという結果が出されたとしても、それは検査回数による影響を受けているとも考えられます。この対処法としては、研究参加者の心臓疾患の検査回数を統一させることが挙げられます。
3)交絡(こうらく)バイアス
単に「交絡」とも呼ばれることもあります。 交絡とは、もとは英語のConfoundingで、混乱させるとか混同させるという意味です。研究では、たいていは原因と予想されるものと結果の間に因果関係があるのかを明らかにしようとします。特に病気の原因を探り、その因果関係を明らかにするのが疫学研究です。そのとき原因でも結果でもない研究しようとしていない第3の要因によって、検討している因果関係が影響を受けることを指します。その第3の要因を 交絡因子や交絡変数と呼びます。例えば、飲酒が下咽頭(かいんとう)がんの要因なっている、という報告があったとします。しかし、実は喫煙そのものが下咽頭がんの発ガンに影響していて、 喫煙によって飲酒量が増えていたことから、飲酒量が多いと発ガンに関係しているように見えてしまったという「見せかけ」の関係性であったと考えられます。
この場合、「飲酒→下咽頭がん」ではなくて、「飲酒⇔喫煙→下咽頭がん」で、飲酒が交絡因子となって見かけ上そのように見えたということです。これは、喫煙者が多く飲酒しているという情報がない場合はうっかり信じられてしまう危険性があるということです。この場合、飲酒をやめたり減らしてもタバコをやめなければ効果はないわけです。したがって、交絡バイアスは結論を間違う大きなミスにつながりますので、とても注意しなくてはならないものです。
4)交絡バイアスへの対処方法
交絡バイアスを生じさせる要因はたくさん考えられます。気がつかないものもあり得ますが、実験や調査を行う前から、交絡因子となりやすいものは事前に対処するようにします。その代表は、薬など治療の効果を明らかにする実験研究でのプラセボ効果です。それ以外で不可欠なものは、性別と年齢です。順番に見ていきます。(1)プラセボ効果とマスキング(盲検/ ブラインド)
プラセボとはいわゆる「偽薬」のことです。みなさんは薬を飲む時に「この薬は効く」と思って飲みませんか? この「効く」という気持ちだけで本当に治ってしまうこともあります。これを「プラセボ効果」といいます。薬というのは化学的作用の他に、心理的な効果もとても大きいのです。これは効果を期待することやパブロフの犬で知られる条件反射で、脳が薬を飲んだ時のように働くことで起こると考えられています。さらに、これは薬を与える医師の態度によって大きくなることもあると指摘されています。一所懸命にこの薬は効くんですと言われれば、効果がある気が高まります。したがって、新しい薬や治療法の有効性を調べる時にはこの薬(もしくは治療法)の効果なのか、「プラセボ効果」なのかを考えなくてはいけません。そのため、実験群(本当の薬・治療法を受けている)とプラセボ群(研究者が薬を与えるふり・治療をするふりをしている)にわけ、その効果を確かめています。
実験の中にはプラセボ群を作っていない実験もあり、その場合その研究で効果があるといわれているものは科学的に効果があるのかを考える必要があります。
このような、実験により参加者や実験者がうける心理的要因による影響であるプラセボ効果を取り除くための対処法としてマスキング(盲検/ブラインド)が挙げられます。
例えば、ある新薬Aの効果を確かめる実験で、新薬Aと外見がそっくりな偽薬(プラセボ) を用いることで、参加者にはどちらが新薬Aでどちらがプラセボか知らせないで医者が渡し、使用する場合、単盲検(シングル・マスキング)といいます。
さらに医者とは別のこの実験の企画、実行している研究者が、担当の医師にもどちらが本物でどちらが偽物かを隠して患者に渡す場合、二重盲検(ダブル・マスキング)といい、よく行われています。なぜなら、渡す人がどちらがどちらかを知っていると、態度や言葉に知らないうちに出る可能性があるからです。それはプラセボ効果の大きさに影響するかもしれません。
二重盲検に加え、薬を渡す医師だけでなく、データを分析する人にもどちらの人が新薬を飲んだ人なのかを隠して結果を出す場合、三重盲検(トリプル・マスキング)といいます。データを分析する人が結果を出したいあまりに、万が一ねつ造したり、分析方法を結果が出やすいものにしたりすることを防ぐことになります。
(2)マッチングと無作為(ランダム)化
交絡要因として性別や年齢があるのは、それが健康状態と強く関連していることからわかると思います。これらは、実験や調査の前からわかることが多いので、例えば実験で治療を行う群と行わない群を比較するときは、交絡要因でそろえるようにします。2つの群を、男女の割合や、年齢の構成割合をそろえて参加者をあつめることで、性別や年齢による結果への影響を除くことができます。このように交絡要因をそろえることをマッチングといいます。2つの群の構成メンバーをマッチさせるということです。また、2つの群を作るときに、コインの表裏やくじ引きなどによって分けることで、理論的には似たような特徴を持つ群に分けられることになります。それでも結果的には偶然どちらかに何かの特徴で偏ってしまうこともあります。しかし、少なくとも分けるときに研究者の意図(たいていはいい結果を出したいという思い)が入っていないということが大切なのです。このような方法で交絡要因をそろえることを無作為(ランダム)化といいます。
(3)そのほかの方法
特別な統計解析方法である、多変量解析という手法によって交絡要因の影響を取り除くことができます。くわしい説明は省略しますが、統計的な方法によって、第3の変数の影響を取り除いて、原因と結果の直接の関係をみることができます。この手法は現在の研究の世界では不可欠なものとなっています。2. 代表的な研究方法とエビデンスレベル
ここではエビデンスを作るために行われる代表的な実験や調査の方法を、エビデンスレベルの低いといわれるものから順番で紹介します。ただし、順番といってもそれほど厳密なものではなく、研究の細かな進め方でバイアスをどれだけ考慮したかによって、レベルが入れ換わることもありえます。1)記述的研究
「この患者さんにこのような治療を行ったら回復した」というような、1人から数人の病気を持った人や対象者のデータを詳細に記述する方法を記述的研究といいます。症例報告と呼ばれることもあります。数が少なすぎるため、その対象者だけに起こったことかもしれないという疑問が必ず残ります。このような研究は原因を明らかにする目的で行われた研究とはいえません。エビデンスとしては十分ではありませんが、これらの研究の結果から多くの問題提起、仮説の提示などがなされ、その後の研究の基礎になります。2)前後比較試験(非比較試験)
症例報告よりはもう少し数を集めたものです。例えば、ある診療所に通う風邪の人たち全員に薬Aを2週間飲んでもらいました。2週間後にほぼ全員の風邪が治っていました。したがって、薬Aは風邪の治療に効果的だということがわかった、という情報は、前後比較試験という実験方法で明らかになったエビデンスと言えます。使用前、使用後、という身体写真が出されている食品や運動器具なども良く見かけますが、それは前後比較による実験結果です。
この実験方法は一見すると効果があったように見えますが、ひょっとすると薬Aを使わなくても風邪は治っていたのではないのかという疑問には答えることができません。というのも、この実験では薬Aを飲まなかった人と比較できないからです。やはりものごとの因果関係を明らかにするには、原因と考えられるものがあった人となかった人で、結果が起こったか起こらなかったかを比較するという方法が必要です。このため、エビデンスレベルとしては低いものになります。
3)症例対照研究
原因の有無で結果の有無を検討できるものです。なかでも比較的容易に効率の良いエビデンスある情報を出すことができる疫学調査として、症例対照研究が知られています。基本的には現在病気の人(症例)と病気でない人(対照群)を比較して過去の生活でどんな出来事の違いがあったのかを比較して原因を探ろうというものです。例えば、ある地域に住んでいる70歳の男性のなかで、身体機能が年齢以上に衰えている100名(症例群)と身体機能が維持されている100名(対照群)を比較します。二つの群で、過去にその地域で行なっていた健康教室に通っていた人の割合を比較します。すると、身体機能が維持されていた人100人のうち健康教室に通っていた人の割合が、身体機能が衰えている人100人の2倍くらいだったということがわかるとします。この結果かたは、その地域では健康教室に通わないと身体機能を維持することが難しくなっているという、エビデンスとなる情報が出されます。
この症例対照研究で気をつけなければならないのは、対照群として選び出す人の特徴です。症例群の人たちと、なるべく性別や年齢、住所などが似ている、人を選び出すことが必要です。しかし、これがなかなか難しいのが欠点で、どうしても選択バイアスが生じやすくなっています。また、一番の欠点としては、過去のことが全員記録されていることは滅多になく、記憶がたよりになるので、「思い出しバイアス」が生じやすいものです。
4)コホート研究
コホートとはもともと古代ローマの軍隊の一単位で、300から600人からなる歩兵隊のことですが、コホート研究という場合は、多くはある一定の地域に住んでいる集団のことです。ある集団をずっと長い間追跡して調べていきます。その人々の間で起こっている健康に関連がありそうな出来事(喫煙、運動習慣、食生活、ストレス、職業生活、人間関係など)がどのように異なるのかを調べておいて、その違いでその後の経過がどうなっていくかを見ていく方法です。例えば、1997年に40歳になった全国のいくつかの都道府県に住む10,000人の男性を10年間追跡します。彼らの中で、定期的に運動習慣をおこなっている人が2,000人いたとして、そうでない8,000人と10年後の状況を比較していきます。運動習慣のある2,000人の中で心筋梗塞を発症した人の割合に比べて、運動習慣がない8,000人の中での心筋梗塞を発症した人の割合がどのくらい違うのかを比べます。例えば、4倍違ったとわかることで、心筋梗塞の発症にはそういった健康習慣がよろしくない、という結果、つまり、エビデンスがある情報がだされます。
とくに世界的に知られているコホート研究は、1948年にアメリカのボストンに近いフラミンガムでスタートしたフラミンガム心臓研究です。5209人を対象に追跡が始まりました。そして、この研究から喫煙、年齢、高コレステロール、高血圧などの危険因子が明らかになったのです。疾患の原因として「危険因子(リスクファクター)」という用語を最初に用いたのもこの研究です。その成果によって、アメリカではその後30年間で発症率を半減させることに成功しています。 現在も続々と次の世代が引き継いで継続されていて、疫学研究の重要さを伝えつつ世界中に大きな影響を与えています。詳しいことは循環器疫学サイトをご覧ください。このサイトにはほかにも日本で行われているコホート研究が紹介されています。
この方法は、症例対照研究のように、選択バイアスや記憶に頼るバイアスなどが少なく、病気の発生率や時期などもわかりエビデンスとして情報が多く得られるものです。何より原因と結果の順序が合っているので因果関係として説得力があります。しかし、どうしても欠点があります。長く追跡していきますので、途中で脱落したり、時代によって生活や価値観、医療水準や診断方法などが変化する影響が避けられません。これらを見落とさないためにも、大人数からいつも情報を得ようとすれば、膨大な人件費や事務費など多額の費用がかかります。したがって、実際には国などの公的な研究機関が中心となって行われることが多いものです。
5)非ランダム化比較試験(NRCT)
ここからは、治療やケアなどを行った人とそうでない人を比較するための実験を行う研究で、エビデンスレベルの高いものです。実験なので、介入を行うグループと行わないグループは、それの有無以外は同じ条件に設定できればバイアスが少ない研究になります。 例えば、薬Aを飲まなかった人と飲んだ人とで、その後どのように胃痛が治っていくのかを比較する実験です。例えばある診療所の午前中に胃痛の診察に来た患者には薬Aを1週間飲んでもらい、午後の診察に来た患者には薬Aは飲まないようにします。その1週間後に薬Aを飲んでいた人はほぼ全員胃痛が治っていたにもかかわらず、飲まなかった人の約半数は治っていなかったということがわかったとします。したがって薬Aは胃痛の治療に効果的だ、という情報は非ランダム化比較試験(NRCT)という実験方法に基づくエビデンスといえます。介入をしているかしていないかを比べた比較試験ではあるのですが、非ランダム化とつくのは、そのグループの分け方の問題です。このグループ分けすることを「割り付け」といいますが、それがランダムでないからです。例えば、午前中に診療に来られるような生活に余裕があるから治って、午後にしか診療に来られない、余裕がない人だからなかなか治らなかったのではないのか、という理屈で疑いをもたれることも考えられます。では逆に設定した場合はどうかということになりますが、結局は午前と午後にまつわる理由は払拭できないでしょう。したがって今回の午前診察、午後診察という、新薬Aをどの患者に内服してもらうかという方法では、疑いを晴らすことはできません。これは、グループに何らかの違いが生じている可能性があるということで、それをなくすためにとられる方法が次のランダム化した割り付けによる比較試験です。
6)ランダム化比較試験
ランダム化比較試験(Randomized Controlled Trial、RCTと略します)とは、そのような疑いをもたれないように、介入するグループとしないグループを決めて実験を行う方法です。具体的には、すでにどちらのグループに入るかが書かれた封筒を人数分用意し、診療に来た人順に、それを開けていって割り振るとか、コンピュータで乱数を発生させて偶数奇数で判断するとか、その数字を頼りに決めるものです。しかし、封筒を使う方法は、信頼が低く使われないようになってきています。なぜでしょうか。例えば、重症と思われる患者さんが来たときに、封筒を開けて治療しないほうに当たった場合、気の毒に思って変更してしまうということがあり得る(実際にそのように思える研究が見られた)という話です。したがって、人の手を通さずにコンピュータで機械的に分けるという、なるべく人の意図が入らない方法が用いられます。ランダムというのは、無作為という意味、すなわち人の意図が入らないということで、できる限りバイアスがないことを実現しようという努力なのです。
ランダムに決めることで割り付けにまつわる疑いを晴らすことができ、RCTによる実験結果は信憑性の高い、エビデンスのある情報といえます。
さらに言えば、さらに上の最高のエビデンスは、このRCTを複数行った結果を、一つにまとめた結果も効果が認めれるものです。このまとめる方法をメタアナリシスといいます。高次の分析、分析の分析といえるもので、考えられた技術を使って最終結論を導こうとするものです。公開されている各種ガイドラインやコクランライブラリーなどは、これらの方法を使った高いエビデンスが結集されたものになります。
エビデンスレベルをまとめると次のようになります。 患者データに基づかない専門家・委員会の報告や意見が最も低いものとなっていることにも注目してください。研究対象として人のデータに基づいていないものは、検証されていない専門家の考えでしかないということです。データを示さずに話をする専門家、1回の研究だけでものを言う専門家を批判的に見ることが大切です。
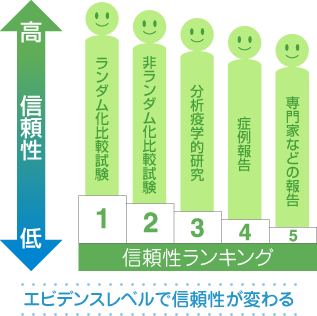
↑高いレベル
(1) ひとつ以上のランダム化比較試験
(2) ひとつ以上の非ランダム化比較試験(NRCT)
(3) ひとつ以上の分析疫学的研究(コホート研究や症例対照研究)
(4) 症例報告などの記述的研究
(5) 患者データに基づかない専門家・委員会の報告や意見
↓低いレベル
3.結果の偶然性と対象者数
インターネット上や本、雑誌にあるエビデンスに関する情報を見るときに、よく出てくる、とても重要で知っておきたいものとして、アルファベット1文字であらわされる「p」と「n」があります。ここでは簡単にこれらについて説明します。1)「p」・・・偶然なのか必然なのか~治療の効果の有無の指標のひとつ
A大学のB教授がある臨床試験をしました。そこでは、ある治療法によってある検査値(たとえば血圧や肝機能に関する指標)の改善という効果があったのかみきわめるとき、ある治療法は大半の人には効き目がなかったはずなのに、偶然にその人には効いてしまった、改善してしまった、という解釈も考えておかなければなりません。こうした事態を引き起こしてしまう「確率」を、統計学の手法を用いることで計算することができます。この確率を英語のprobability(確率)の頭文字をとってp値(ぴーち)といって数字で表すことができます。この確率が小さいほど、偶然に効いてしまったのではなくて、必然的に効いたと言うことができます。一般的にp値は5%(0.05)未満であれば、「統計学的に有意(ゆうい)」と言って、統計学的にも偶然に効いたのではないという事を示すことができます。p値は効果があったのかなかったのか(ある検査値や寿命などに差が生じたのかなかったのか)という観点からの治療効果の「有無」の表示ですが、効果の「大きさ」を表示する方法も大切です。たとえば、ある治療によって、治療しなかった人よりも2倍苦痛が緩和できた、というように何倍というような「比」や、血圧の平均値が10下がったというような平均値の「差」などが代表的です。こういった数字もひとつの効果の「大きさ」の表示方法です。こういった数字は「効果サイズ」と呼ばれています。この効果のサイズは、その実験の対象者のデータから計算することができます。
しかし、その結果ははたして今回、実験の対象者にならなかった人たちにおいてもあてはまる数字なのでしょうか?言い換えれば、その効果のサイズは一般的といえるのでしょうか?こうした疑問に答えてくれるのが「95%信頼区間」です。これは95%の確率で、本当の一般的な効果のサイズを「含まれる間隔」という形で示すものです。100回この実験を行ったとき95回はこの範囲の中に効果のサイズはおさまりますよ、という示し方です。統計学的な方法を使って一回の実験結果からこの範囲を求めることができます。
例えば、2.0(1.2-3.2)と後ろにカッコで示されていれば、効果サイズは2.0倍で、その信頼区間は最小で1.2、最大で3.2の幅に入るということです。この間隔が狭いほど、その実験で得られた効果のサイズをより信用できることになります。この例の場合は、最小で1.2なので、ここが1.8になっている実験のほうが2.0倍という数値が信頼できることになります。
2)「n」・・・エビデンスの元となる実験に参加した人の数
エビデンスの元となる研究論文を見る際に、「n=100」といった「n=」という言葉が良く出てきます。また、医師や研究者は「n数が100人で」というような言葉を用いる場合もあるかもしれません。この「n」とは、number(数)の頭文字で、その研究の対象者の数のことを指します。たとえば、ある治療法が1人に行われた結果1人に効果があったというデータよりも、100人に行われた結果100人に効果があったというデータのほうがより信用できそうですし、1万人に行われた結果1万人に効果があったというほど、より信用できそうです。なぜならば、私たちはその結果がより一般的に、誰にでもあてはまる、そして自分やある患者さんにもあてはまる、という結果を求めているからです。1人中1人に効果があったというデータは、偶然だったのではないかと疑います。研究論文にあるエビデンスはこのように、その介入の結果が偶然だったのか、必然だったのか、ということをみきわめる作業をしています。その作業において、n数は大きな役割を果たしています。
3) nとpの関係
「n」と「p」あるいは「信頼区間」は実は深い関係にあります。nが大きくなるとpは小さくなります。nが大きくなると「信頼区間」は狭くなります。p値を計算する方法は、差をみたい、たとえば検査指標や比率など、その数値の性質によって異なります。しかし、それぞれの計算方法はでは、いろんな形でn数を使用します。そしてn数が大きくなるほどp値が小さくなりやすいという結果になります。たとえば、以下の例のような結果があったとします。
表1
|
改善 |
改善せず |
計 |
治療したグループ |
7 |
5 |
12 |
治療していないグループ |
3 |
10 |
13 |
計 |
10 |
15 |
25 |
表1のとき、治療したグループであるほど改善しているといった効果のp値(カイ2乗検定)を計算するとp=0.3527という値になります。0.05より大きいので改善しているとは言えません。
次に以下の例を見てみましょう。
|
改善 |
改善せず |
計 |
治療したグループ |
21 |
15 |
36 |
治療していないグループ |
9 |
30 |
39 |
計 |
30 |
45 |
75 |
表2の数字は、表1の数字をそれぞれ単純に3倍した数字になります。この場合改善している効果のp値は、p=0.02134となって0.05より小さいので統計学的に改善していると言えます。
このように同じ人数割合であっても実数が増えることによって、結果が変わってきてしまいます。
4)nと信頼区間の関係
95%信頼区間とはある実験で得られた数値をもとに、世の中一般にあてはまる数値の範囲を示したものです。正確には同じ実験を100回繰り返した時に、95回の結果が含まれる範囲と言えます。この範囲はn数によって左右されます。n数が大きくなるほどその幅が狭くなります。先ほどの表1、表2の例を見てみましょう。計算すると、治療したグループの改善度は、治療していないグループの改善度の2.53倍であることが分かります。人数割合が一緒なので、表1も表2も同じ2.53倍です。
しかし、表1のデータの場合、95%信頼区間を計算すると、0.84~7.61になりますが、表2のデータの場合は1.34~4.77と幅が狭まります。さらに表1のデータのn数を100倍した時のデータを以下に示します。
表3
|
改善 |
改善せず |
計 |
治療したグループ |
700 |
500 |
1200 |
治療していないグループ |
300 |
1000 |
1300 |
計 |
1000 |
1500 |
2500 |
改善度の比は同じく2.53倍ですが、信頼区間を計算すると、2.26~2.82と一層狭まります。これは信頼区間の計算でn数が大きく関与してくるためなのですが、要はn数が多い結果であるほど、その結果の確からしさが高まる、逆に少ないn数のデータからは確実なことが言いにくい、ということになります。
5)nが多いとそれでよいのか
nが多いほどp値も低くなり、信頼区間も狭まり、確かなことが言える、ということを述べてきました。では、とにかくn数が多ければ多いほど良いということなのでしょうか。しかし、本来効果がないはずなのに、n数が多いためにp値が小さくなってしまって「統計学的に有意」という結果として示されることも考えられます。そこで、少なからず多からず適切なn数のもとでの実験が望まれます。こうした適切なn数については研究によって異なりますが、ある方法を使用すると計算することができます。つまり、参考にしようとしているエビデンスが信頼のおけるものかどうかを把握するためには、載っている研究論文ではきちんとしたn数のもとで行っているのか、つまり、そのエビデンスは適切なn数のもとで打ち出されているのかをチェックすることが大事です。
このような統計学の考え方や方法は、とても大切なもので、エビデンスを生み出したり評価する時に統計学は不可欠です。しかし、統計学は、偶然ではないかとか、誤差はどれほどかを教えてくれますが、効果の大きさの意味については教えてくれません。したがって、例えば、2.53倍といっても、その数値もつ意味について考えてみることが大事です。表3の場合、その治療では2.53倍良い結果が出ているのですが、治療していなくても300名が改善していますし、治療しても500名が改善していません。この結果をどのようにとらえるのかは一概にはこたえることができません。この治療にまつわる、たとえばコストや副作用など、さまざまな観点から、みなさんが総合して考え、捉えないといけないわけです。
そのとき、効果と言っても、何を効果と考えているのかも大切です。たとえば、がんに対する薬の効果と言うと、がんが消えて無くなることをイメージするかもしれません。しかし、がんが大きくならないことを効果と考えることも可能ですし、痛みを緩和する効果かもしれません。ダイエット効果という場合も、体重が減少したとしても、水分も筋肉も脂肪も減少しているのか、脂肪だけ減少しているのかでは大きな違いです。その確認も忘れてはいけません。
4.母集団とサンプルの代表性
たとえばA病院に通院する患者さんを対象として病院の満足度調査を行ったとします。その結果、「満足」もしくは「やや満足」と回答した患者さんは、回答者全体の80%であったとします。この80%はA病院の患者さんの満足度、といえるのでしょうか。これを考えるとき、まず、この満足度調査に誰が参加したのかを知る必要があります。A病院に通院する全員が参加していたら、それでよいかもしれません。しかし、たとえば、A病院の内科に通院する患者さんばかりが参加していたら、A病院全体でなくて、A病院の内科の満足度でしかないかもしれません。
A病院に年間通院する患者さんは全部で1万人くらいいる大きな病院であったとしたら、1万人全員に聞くのは大変なことです。そこで、この1万人のリストから、たとえば1000人の代表者を選んでこの代表者の意見を聞きます。この代表者の意見を全体の意見というような形で理解します。この代表者のことを研究の世界では「標本(サンプル)」といい、1000人の代表者の集まりを「標本集団」といいます。代表者の選び方を「標本抽出法(サンプリング法)」といいます。そしてA病院に通院している患者さん1万人全体のことを母なる集団「母集団(ぼしゅうだん)」といいます。「母集団」とは、その結果(エビデンス)がまんべんなく通用すると考えられる範囲の人たちのことを言います。
この代表者の選び方が重要で、内科に偏りすぎず、外科にも眼科にもまんべんなく参加してもらわなければいけません。そのようなとき、乱数という規則性がない数字を用いて、1万人のリストの中から誰もが等しい確率で参加するという前提のもとで選び出します。この方法を無作為抽出法といいます。この方法をとらない限り、選択バイアスが生じる可能性があるわけです。この方法を行っても、実際には調査を依頼しても断られるなどで、対象になれなかった人が生じます。そのときは、どのような人が断ったのか理由は何かなどもどのようなバイアスが生じているのかを知る上で貴重な情報になります。
では、ある肺がんの治療法を行ったところ効果があった、というランダム化比較試験の結果(エビデンス)があったとします。この結果をよくみたところ、B病院の呼吸器外科に通院する50歳から60歳までの女性70名でかつステージⅡ(がんの進行と広がりの度合い)の人が参加した研究の報告でした。この報告の母集団はどのあたりと考えればよいのでしょうか。正確にはB病院に通院する患者のうち、呼吸器外科に通院し、50歳から60歳までの女性で肺がんのステージⅡという集団、ということが言えます。
では、B病院ではなく他の病院でもこのエビデンスは通用するのでしょうか。必ずしもそうは言うことができません。このような場合は、ほかの報告にあたってみることが大事です。同じ治療法を別の病院で同じような人たちに試していて、それでも効果が見られた、という報告が複数見られていたら、B病院や検討された病院以外でも通用する可能性が高まります。 しかし、そうでなく、逆に効果が見られなかった、という報告があるかもしれません。そういう場合はその治療法については慎重に考えていく必要があります。
このように、そのエビデンスはどの母集団を念頭に打ち出されているものなのか、というところを読みとっていくことが大事です。
(戸ヶ里泰典、中山和弘)
[参考文献・ウェブサイト]
高木廣文, 林邦彦:エビデンスのための看護研究の読み方・進めかた. 中山書店. 2006.
大木秀一:基本からわかる看護疫学入門. 医歯薬出版. 2007.
斉藤武郎EBNが分からなかったあなたへ(オンライン)http://homepage3.nifty.com/saio/EBN-THCQ3.pdf , (参照2008年4月2日)
宮口萌:EBMによる患者中心の医療(オンライン)http://www.kango-net.jp/nursing/03/index.html , (参照2008年4月2日)
コメント
私は、企業に勤める看護師です。
以前、新聞記事やテレビに「悪玉コレステロールが、高い方が長生きする」と言う報道がされました。
会社でも、コレステロール値を下げる薬を飲んでる方が、新聞記事のコピーを持参され、薬は飲まなくても良いのでは?と言ってきました。
現在、痛くも痒くもない身体的な状態なので、すぐに薬を止めたからどうなる訳でもないのですが・・・
色んな情報の中から選択し、自分の健康を維持していかなければなりません。
エビデンスレベルを知って、選択出来る事で、より賢い患者になれるのではないかと思います。
今回、いろんな角度から、信頼出来る情報を選べる術を学べて、よかったです。ありがとうございました。
ボケな~す 2011年5月28日17:41
バイアスの種類とエビデンスレベルについて学ぶことができました。今回の記事を見てもやはりバイアスについてもエビデンスレベルについても複雑ですぐに理解することが難しいと感じました。これだけ複雑な手順を超えて提唱されている研究については正確性や信頼性の高い情報であるということがよくわかりました。逆によくテレビなどで行われる実験は本当に信頼していいものなのかきちんと考える必要があると感じました。
りんご 2013年3月29日16:40
学生や一般市民であれば普通論文の内容は何の疑いもなく信じてしまいます。しかし実は様々なバイアスがかかっていて、有名な大学の教授が書いた論文だからと言って、正しいとは限らないのだと改めて考えさせられました。論文の内容を全て検証することは、きちんとした知識がなければできないことですが、どの様なバイアスがあるのか知っておけば論文を鵜呑みにするということはなくなるだろうと考え、この記事で取り上げられていたバイアスやエビデンスレベルについては今後も覚えておきたいと思いました。
サクラ 2013年5月 2日14:46